项目案例
CourseSnap
课程内容采集与 AI 学习资料整理工具
我的角色
产品定义 / MVP 设计 / 原型设计 / 功能取舍 / AI 工作流设计
项目阶段
可运行 MVP / 个人产品实践
关键结果
约 10 小时完成可运行 MVP,打通自动截图、PDF 合成与 AI 总结的端到端学习资料整理流程。
背景:从真实学习场景出发
CourseSnap 起点来自一个非常具体的学习场景:很多网课、讲座或会议回放无法直接下载完整课件,用户只能手动截图保存 PPT 页面。这个过程低效、容易漏页,后续整理也很困难。最初我想解决的不是做一个复杂 AI 产品,而是先让课程资料更容易被保存和复习。
用户痛点:资料不是没有,而是难以整理
用户在课程结束后通常会拥有很多分散材料:截图、课件、逐字稿、笔记、聊天记录等。问题不只是“能不能识别文字”,而是这些材料很难被组织成一个可阅读、可复习、可继续交给 AI 处理的结构化输入。
- 手动截图效率低,容易漏页。
- OCR 对 PPT 截图识别不稳定,容易乱码、漏字、顺序混乱。
- 图片太分散,不适合阅读和复习。
- 逐字稿与课程画面分离,AI 总结缺少完整上下文。
MVP 方案:自动截图 → PDF → AI 总结
我将产品流程收敛为三步:自动截图检测课程页面变化,只保存新的 PPT 页面;PDF 整理将截图按顺序合成为 PDF,保留课程视觉结构;AI 总结检测 PDF 与 TXT/DOCX 逐字稿,生成结构化学习笔记。最终流程是:自动截图 → 一键合成 PDF → 放入逐字稿 → AI 总结。
PRD 摘要
| 功能 | 用户痛点 | 功能方案 | 优先级 |
|---|---|---|---|
| 自动截图 | 手动截图效率低 | 页面变化检测,自动保存 | P0 |
| PDF 合成 | 图片分散不便阅读 | 按顺序合成为 PDF | P0 |
| 逐字稿检测 | AI 总结缺上下文 | 检测 TXT/DOCX 是否存在 | P1 |
| AI 总结 | 整理学习资料耗时 | 生成结构化学习笔记 | P1 |
| OCR 功能 | 识别不稳定 | 暂不作为核心链路 | P2 / 放弃 |
用户流程
开始录制
检测页面变化
自动保存截图
一键生成 PDF
检测逐字稿
AI 总结
导出学习笔记
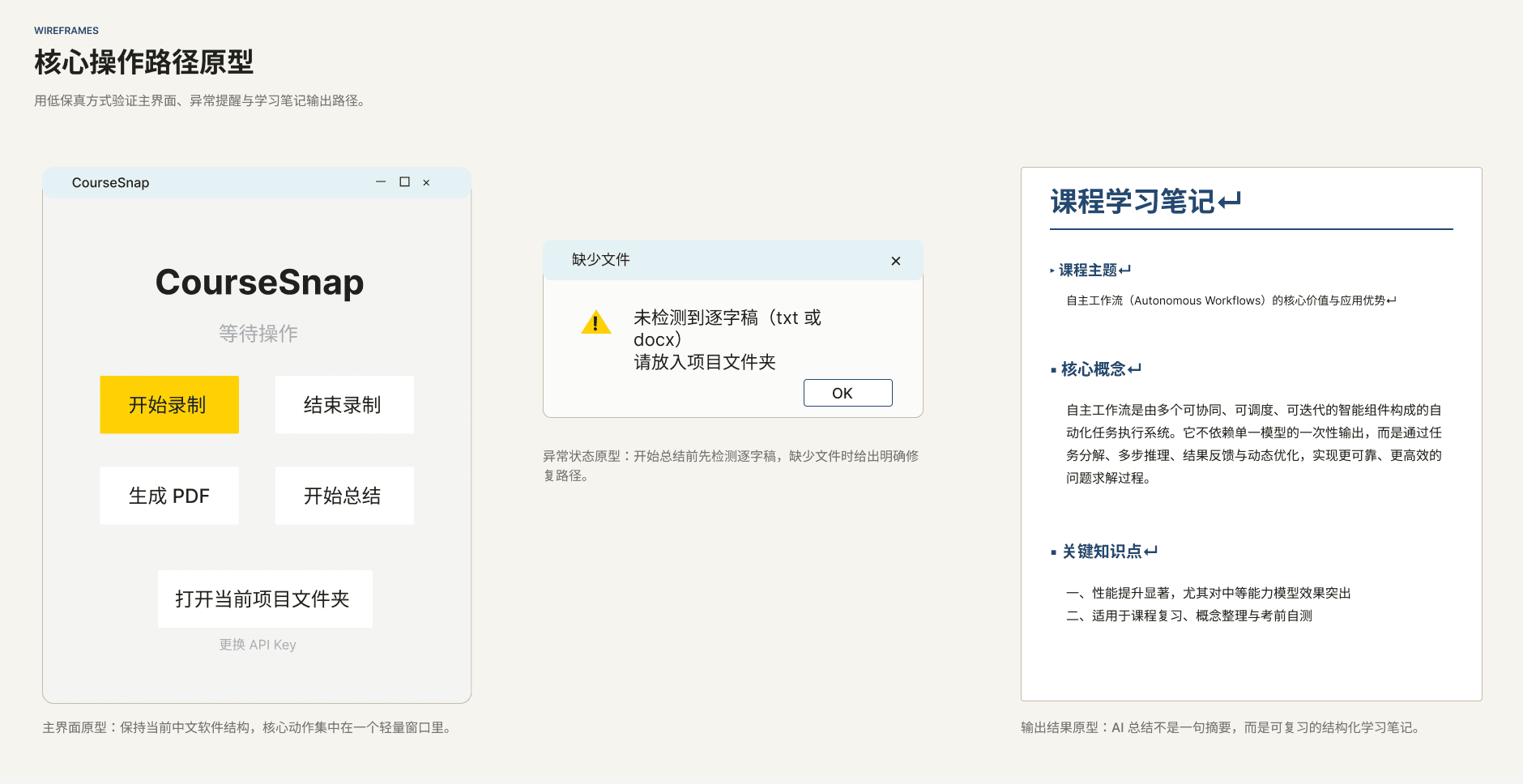
核心界面原型
原型图
低保真 Figma 原型
我用低保真原型先梳理主界面布局、按钮位置和关键弹窗,验证用户能否顺利从“开始录制”走到“AI 总结”。
交互重点
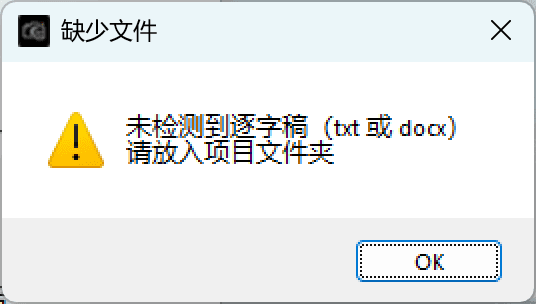
状态与异常先行
我优先设计录制中、缺少逐字稿、输出完成等关键状态,确保用户在每一步都知道下一步该做什么。
真实界面截图/输出


关键产品决策:让 AI 服务真实流程
这个项目最重要的部分不是功能堆叠,而是在有限时间里判断哪些链路应该自动化,哪些环节应该保留人工控制,哪些能力可以独立提供价值。
- 为什么放弃 OCR:早期方案是“截图 → OCR → 文本 → AI 总结”,但 OCR 对课程截图不稳定,容易丢失 PPT 的版式、顺序和视觉信息。我最终放弃把 OCR 作为核心链路,改为用 PDF 保留原始视觉结构。
- 为什么采用 PDF + 逐字稿:PDF 保留课程画面的上下文,逐字稿补充语义内容,两者组合比单独 OCR 更适合作为复习材料和 AI 总结输入。
- 为什么 API Key 由用户输入:AI 功能需要调用外部模型。如果在应用里内置个人 Key,会带来安全、成本和维护风险;让用户输入自己的 Key 更适合个人工具的分发方式。
- 为什么 AI 是增强功能而不是使用门槛:PDF 生成功能本身就能解决资料整理问题,用户即使不用 AI,也能获得明确价值。AI 总结只是在资料整理完成后进一步提升效率。
技术与实现
这个 MVP 是一个 Python 桌面工具。我使用 PIL / ImageGrab 进行屏幕截图,通过页面变化检测避免重复保存相同页面,并将截图按顺序保存。随后,工具可以把图片合成为 PDF,并自动检测项目文件夹中的 PDF 与 TXT/DOCX 逐字稿。AI 总结部分使用 DashScope 兼容 OpenAI 接口完成调用,最终通过 PyInstaller 打包为 Windows 可运行程序。
结果
我约 10 小时完成了可运行 MVP。产品从一个自动截图工具,迭代为“课程资料采集 → PDF 整理 → AI 总结”的完整学习资料整理流程,完成了从用户痛点、产品方案、原型设计、技术实现到交互打包的端到端实践。这个项目的价值不在于堆叠 AI 功能,而在于把 AI 放进一个用户已经存在、但效率很低的学习资料整理流程里。
复盘:AI 产品不是堆功能,而是优化输入与流程
这个项目让我意识到,AI 产品的关键不只是模型能力,而是输入质量、流程设计和用户信任。很多时候,真正影响结果的不是能不能调用 AI,而是用户是否能轻松把高质量材料放进流程,并得到稳定、可理解、可继续使用的输出。
下一步迭代计划
01
自动截图优化
我发现对于带字幕的视频,即使画面未变化,字幕更新也会触发新的截图。下一步,我计划优化截图逻辑,只在关键页面内容变化时截屏,同时保证字幕信息不会丢失,从而减少多余截图,提高用户复习效率。
02
AI 总结逻辑优化
目前,如果用户没有逐字稿,AI 总结功能会受限。下一步,我打算让 AI 总结功能仅提醒用户缺少逐字稿,说明放入逐字稿可以优化总结效果,但仍允许用户选择继续使用 PPT 生成学习笔记。这样既保留用户控制权,也提高功能可用性和灵活性。